Whenever you write something with http://www.xyz/ in it, or x.y@blah.com most computers recognise that this is a web address or an email address and turn them into an active link - clicking on them will open the web page or launch a new email message.
In Twitter, and in similar programmes, adding # in front of a word does two things. It turns the word into an active link (clicking on it from within Twitter or Twitter app will take you to the search page containing all instances of that hashtag) and it also collects up all instances of it that can be shown together (ie aggregates the tweets containing the hashtag).
This means that other aggregators, such as WTHashtag (What the Hashtag) or Twapperkeeper - examples below, can take the feed and present it on their page (ie syndicating the content on another page) - this is basically what RSS feeds do. RSS generally stands for 'really simple syndication'.
Examples
Twitter search, for #ADA2010 tag which corresponds to the American Diabetes Association conference tweets (note that # is expressed as %23) http://twitter.com/home#search?q=%23ada2010
wthashtag for ADA2010 (note that it picks up the #tag but removes the # from the URL)
http://wthashtag.com/Ada2010
Monday, 28 June 2010
Sunday, 27 June 2010
Puzzling inability to access wifi - hoping it's short lived
Neither my Acer Aspire One notebook nor my iPhone can connect to my wifi. In the case of the iPhone it persists in asking for the password, I put it in, it connects, a few seconds later it boots me off and asks again. With the notebook it connects by itself as and when it feels like and the connection persists for a few minutes. When I try and refresh the available wireless networks it fails to spot my Home Hub.
When I connect the cable up to the notebook the speed is fine (8mbps) and all works well, but it's a bit annoying being tethered.
Things that have changed recently are that I've signed up to something or other with BT that means my Broadband speed might increase, so possibly they are 'doing something' with my line. I happened to be out overnight earlier in the week so switched off the home hub for about 36 hours, can't imagine that's made any difference as I've done this before.
There's also been at least one Windows update in the last week which is a lot more likely, from previous experience, to muck things up.
I'm not sure if I should try and do anything - watching and waiting might be the better option at the moment.
Kind friends have suggested I tweak the channel on my wifi card - I've actually no idea how to do this and, in a rare Google fail, I've not found the instructions. But I'm not sure that tweaking my laptop will help as I'd also have to do something to my iPhone and I've really no idea how to configure that.
During the five minutes or so in which I've written this post I've had the pop ups telling me that I'm connected with an excellent signal and then telling me that it cannot connect to my preferred network.
Immensely frustrating!
HomeHub-related suggestions most welcome.
When I connect the cable up to the notebook the speed is fine (8mbps) and all works well, but it's a bit annoying being tethered.
Things that have changed recently are that I've signed up to something or other with BT that means my Broadband speed might increase, so possibly they are 'doing something' with my line. I happened to be out overnight earlier in the week so switched off the home hub for about 36 hours, can't imagine that's made any difference as I've done this before.
There's also been at least one Windows update in the last week which is a lot more likely, from previous experience, to muck things up.
I'm not sure if I should try and do anything - watching and waiting might be the better option at the moment.
Kind friends have suggested I tweak the channel on my wifi card - I've actually no idea how to do this and, in a rare Google fail, I've not found the instructions. But I'm not sure that tweaking my laptop will help as I'd also have to do something to my iPhone and I've really no idea how to configure that.
During the five minutes or so in which I've written this post I've had the pop ups telling me that I'm connected with an excellent signal and then telling me that it cannot connect to my preferred network.
Immensely frustrating!
HomeHub-related suggestions most welcome.
Dettol kills extremophiles. Fact. (Maybe)
Here we go. Another blog post to put down some thoughts before complaining to the Advertising Standards Authority about a strange claim made by Dettol in a recent advert.
I didn't get the exact phrasing but it seemed to be along the lines of bacteria can survive in lava so some of them are a bit indestructible but fear not, for Dettol can get rid of them on your kitchen surface.
I have some questions that I want to investigate, before having a formal whinge, which are...
1. Can bacteria survive in lava?
Lava's pretty hot (quite a bit hotter than those hydrothermal vents I think?) so I wouldn't be surprised if they'd struggle to survive in the sort of lava that's pumping out of an active volcano. Equally, bacteria have turned out to be fairly flexible in the range of environments they can surve in and Wikipedia has a long list of the various 'extremophiles' (http://en.wikipedia.org/wiki/Extremophile), so maybe they can.
Of course, lava's only hot for a short time. It soon cools (and as an interesting aside the rate at which it cools determines the type of volcanic rock it produces). Cool lava can presumably contain the sort of bacteria that like to live inside rocks; apparently these are called endolithic bacteria. I don't know though if the bacteria move in at a particular temperature, or if they manage fine at any temperature of lava, even at its hottest.
2. How common are these bacteria? Do they live on my kitchen surface?
I'm assuming the sorts of bacteria that like living in volcanic rock aren't the same ones that I'll find in my kitchen. It doesn't particularly matter if Dettol can kill these bacteria if the bacteria are nowhere to be found in my flat. Question 2b is 'can Dettol kill lava-dwelling endoliths?' which is not a question I expected to be asking myself when I woke up this morning.
3. Is it appropriate for Dettol to draw these inferences from 'badass' bacteria? (See Youtube comments)
@medtek and @jdc325 have kindly sent me a link to the original advert so I can check the exact phrasing and amend this blog post later (those dishes won't wash themselves...)
Dettol Complete Clean Advert
http://www.youtube.com/watch?v=DCOSFTugYZM
Clearly they are implying that some bacteria are 'tough' and require firm handling, but I thought the tone of the ad was a bit overkill. Question 3b is 'how effective is soap and water at getting rid of surface bacteria?'
I didn't get the exact phrasing but it seemed to be along the lines of bacteria can survive in lava so some of them are a bit indestructible but fear not, for Dettol can get rid of them on your kitchen surface.
I have some questions that I want to investigate, before having a formal whinge, which are...
1. Can bacteria survive in lava?
Lava's pretty hot (quite a bit hotter than those hydrothermal vents I think?) so I wouldn't be surprised if they'd struggle to survive in the sort of lava that's pumping out of an active volcano. Equally, bacteria have turned out to be fairly flexible in the range of environments they can surve in and Wikipedia has a long list of the various 'extremophiles' (http://en.wikipedia.org/wiki/Extremophile), so maybe they can.
Of course, lava's only hot for a short time. It soon cools (and as an interesting aside the rate at which it cools determines the type of volcanic rock it produces). Cool lava can presumably contain the sort of bacteria that like to live inside rocks; apparently these are called endolithic bacteria. I don't know though if the bacteria move in at a particular temperature, or if they manage fine at any temperature of lava, even at its hottest.
2. How common are these bacteria? Do they live on my kitchen surface?
I'm assuming the sorts of bacteria that like living in volcanic rock aren't the same ones that I'll find in my kitchen. It doesn't particularly matter if Dettol can kill these bacteria if the bacteria are nowhere to be found in my flat. Question 2b is 'can Dettol kill lava-dwelling endoliths?' which is not a question I expected to be asking myself when I woke up this morning.
3. Is it appropriate for Dettol to draw these inferences from 'badass' bacteria? (See Youtube comments)
@medtek and @jdc325 have kindly sent me a link to the original advert so I can check the exact phrasing and amend this blog post later (those dishes won't wash themselves...)
Dettol Complete Clean Advert
http://www.youtube.com/watch?v=DCOSFTugYZM
Clearly they are implying that some bacteria are 'tough' and require firm handling, but I thought the tone of the ad was a bit overkill. Question 3b is 'how effective is soap and water at getting rid of surface bacteria?'
Wednesday, 23 June 2010
Making job recruitment a bit easier - suggestions
A short blog post arising because of my frustrations with the world not being as I would like it to be...
The English language affords us many words to get our points across but in the field of job vacancies its expansive repertoire might be more of a hindrance. As you may know, I run the @scicommjobs vacancies listing and have been collecting vacancies pages for employers of science communicators for the last seven years (http://is.gd/1KPor). Periodically I look at these pages to see if any new jobs are being advertised - many are also advertised in the mainstream media as well as certain mailing lists, but many are not.
In Jo World there would be an agreed word, perhaps 'jobs' and all websites would set their search engines so that searches for vacancies, recruitment, opportunities, 'work for us' and 'work with us' would all point towards 'jobs' and not return 'page not found'.
Secondly, all organisations would have a dedicated jobs page, possibly a sub-page of 'About Us' which most organisations already have. Some organisations advertise their jobs in the news section which is fine, but I can't see that it's a great deal of work to have a permanent page (even if it has nothing on it for ages until a vacancy appears).
Thirdly, let's pipe some RSS feeds from vacancies pages. I'd love to be able to send organisations' feeds to my blogpost* linked above so that when I look at it, the new jobs ping up - saves a bit of clicking. I think the benefits of this go beyond telling people there's a job that they may or may not want - the RSS adds content to the world, with your brand on it.
*I'm not actually sure if this is possible in Blogger, though it works quite well in Wikispaces http://skepticmedia.wikispaces.com/Events - I didn't add the Glasgow event (at time of writing one is coming up on 30 June), I merely added the widget that will update an RSS feed when a new event is posted.
Fourthly - and I accept that I might be on my own on this one - have an archive of all your job descriptions so people can see the range of jobs that your organisation has (even if not available) and can see, well in advance, the sorts of skills and experience required for a job that they may be interested in. This last point is primarily why the ScicommJobs Posterous exists - I've taken matters into my own hands ;-)
I think any or all of these would make it a little bit easier for people to find out about jobs, and to set up automated systems (reading RSS feeds) to keep an eye on what they're interested in.
The English language affords us many words to get our points across but in the field of job vacancies its expansive repertoire might be more of a hindrance. As you may know, I run the @scicommjobs vacancies listing and have been collecting vacancies pages for employers of science communicators for the last seven years (http://is.gd/1KPor). Periodically I look at these pages to see if any new jobs are being advertised - many are also advertised in the mainstream media as well as certain mailing lists, but many are not.
In Jo World there would be an agreed word, perhaps 'jobs' and all websites would set their search engines so that searches for vacancies, recruitment, opportunities, 'work for us' and 'work with us' would all point towards 'jobs' and not return 'page not found'.
Secondly, all organisations would have a dedicated jobs page, possibly a sub-page of 'About Us' which most organisations already have. Some organisations advertise their jobs in the news section which is fine, but I can't see that it's a great deal of work to have a permanent page (even if it has nothing on it for ages until a vacancy appears).
Thirdly, let's pipe some RSS feeds from vacancies pages. I'd love to be able to send organisations' feeds to my blogpost* linked above so that when I look at it, the new jobs ping up - saves a bit of clicking. I think the benefits of this go beyond telling people there's a job that they may or may not want - the RSS adds content to the world, with your brand on it.
*I'm not actually sure if this is possible in Blogger, though it works quite well in Wikispaces http://skepticmedia.wikispaces.com/Events - I didn't add the Glasgow event (at time of writing one is coming up on 30 June), I merely added the widget that will update an RSS feed when a new event is posted.
Fourthly - and I accept that I might be on my own on this one - have an archive of all your job descriptions so people can see the range of jobs that your organisation has (even if not available) and can see, well in advance, the sorts of skills and experience required for a job that they may be interested in. This last point is primarily why the ScicommJobs Posterous exists - I've taken matters into my own hands ;-)
I think any or all of these would make it a little bit easier for people to find out about jobs, and to set up automated systems (reading RSS feeds) to keep an eye on what they're interested in.
Saturday, 19 June 2010
Using IRC (internet relay chat) at conferences, to save hashtagged tweets
About 15 years ago I was a fairly regular user of IRC, at a sort of 'advanced amateur' level on one of the several #London channels; I forget which network though. I really enjoyed it, learned quite a lot about computery stuff and enjoyed the company (both on- and offline) of the chums I met there. I don't remember suddenly stopping using it, but as soon as I got going on Twitter I was reminded of it, and of the similarities.
The main difference though is in effort in getting started - Twitter is exceptionally easy to sign up to and get going, the work comes in connecting with people. With IRC you need to download a client, set it up and join a channel. There are a few commands you need to use as well - it's not difficult but requires a smidge more effort and is a shade geekier than Twitter. I've just used freenode for the first time - it wasn't in the list of available networks so I had to work out how to add it myself, again not difficult but a slight barrier to wider use.
I know that people use IRC as a backchannel at conferences, as well as Twitter, I just don't know if people have been IRCing at any of the conferences I've been to. I'd peg the Science Online ones in London as being likely candidates, but certainly on a much smaller scale if so. Possibly there are certain types of conferences, events or sessions that use IRC - not that surprisingly the #sciencehackday event is using it. The people who whizz high altitude balloons upwards also discuss matters geeky on their freenode channel. Possibly IRC is destined to stay outside the mainstream, unless there are lots of web-based IRC clients I don't know about (familiar only with Pirch and mIRC).
When I entered the #sciencehackday channel I noticed that a bot (robot) was sending anything from Twitter containing the hashtag #scihack to the channel. I thought that was rather clever and wondered if it was something that could be used to save hashtagged tweets from a conference - a topic I've blogged on before:
Following conference hashtag tweets in real time and saving them for later
and TweetNotes - tool for archiving hashtagged tweets at events and conferences etc
I also wondered if it is as straightforward as setting up 'What The Hashtag' (wthashtag) or TwapperKeeper to record a series of tweets. Apparently setting up an IRC bot probably requires a bit of programming knowledge and I may be some time, trying to understand the suggested instructions here http://github.com/tommorris/twittertoirc
To me IRC as a backchannel is analogous to using FriendFeed - with FF it is possible to set up a room in which the search results for a hashtagged tweetstream are posted in real time and which people who are already signed up to FriendFeed can read and comment on, as well as adding their own comments (these aren't pinged back to Twitter).
In that sense IRC and FriendFeed are almost identical but the big difference is that FriendFeed seems to strip out author details meaning that you've no idea who's posted a tweet if it's come via the Twitter RSS. IRC certainly wins here, although the interface isn't quite as pretty.
I see someone else has had similarish thoughts to me:
Wanted: an IRC bot to gateway to a twitter backchannel - http://ideas.4brad.com/wanted-irc-bot-gateway-twitter-backchannel
The main difference though is in effort in getting started - Twitter is exceptionally easy to sign up to and get going, the work comes in connecting with people. With IRC you need to download a client, set it up and join a channel. There are a few commands you need to use as well - it's not difficult but requires a smidge more effort and is a shade geekier than Twitter. I've just used freenode for the first time - it wasn't in the list of available networks so I had to work out how to add it myself, again not difficult but a slight barrier to wider use.
I know that people use IRC as a backchannel at conferences, as well as Twitter, I just don't know if people have been IRCing at any of the conferences I've been to. I'd peg the Science Online ones in London as being likely candidates, but certainly on a much smaller scale if so. Possibly there are certain types of conferences, events or sessions that use IRC - not that surprisingly the #sciencehackday event is using it. The people who whizz high altitude balloons upwards also discuss matters geeky on their freenode channel. Possibly IRC is destined to stay outside the mainstream, unless there are lots of web-based IRC clients I don't know about (familiar only with Pirch and mIRC).
When I entered the #sciencehackday channel I noticed that a bot (robot) was sending anything from Twitter containing the hashtag #scihack to the channel. I thought that was rather clever and wondered if it was something that could be used to save hashtagged tweets from a conference - a topic I've blogged on before:
Following conference hashtag tweets in real time and saving them for later
and TweetNotes - tool for archiving hashtagged tweets at events and conferences etc
I also wondered if it is as straightforward as setting up 'What The Hashtag' (wthashtag) or TwapperKeeper to record a series of tweets. Apparently setting up an IRC bot probably requires a bit of programming knowledge and I may be some time, trying to understand the suggested instructions here http://github.com/tommorris/twittertoirc
To me IRC as a backchannel is analogous to using FriendFeed - with FF it is possible to set up a room in which the search results for a hashtagged tweetstream are posted in real time and which people who are already signed up to FriendFeed can read and comment on, as well as adding their own comments (these aren't pinged back to Twitter).
In that sense IRC and FriendFeed are almost identical but the big difference is that FriendFeed seems to strip out author details meaning that you've no idea who's posted a tweet if it's come via the Twitter RSS. IRC certainly wins here, although the interface isn't quite as pretty.
I see someone else has had similarish thoughts to me:
Wanted: an IRC bot to gateway to a twitter backchannel - http://ideas.4brad.com/wanted-irc-bot-gateway-twitter-backchannel
Thursday, 17 June 2010
Some thoughts on literacy and health literacy
Disclaimer: All views are my own and not necessarily shared by my employers.
Following this tweet
@mjrobbins RT @fivethirtyeight Words like 'earthquake' and 'challenge' elitist as have 7+ letters - CNN "expert". http://bit.ly/cUfOZg
there's been a bit of discussion on Twitter about reading ability and literacy. I posted that I believed something like a fifth of adults had literacy problems but Ed Yong challenged that 'problem' isn't necessarily an appropriate category description and that it's more reasonable to view it as a young reading age and difficulty with certain technical words. Certainly I'd agree that I don't want to apply pejorative categories to people but I think there are people who have more serious difficulties with reading and comprehension, more serious than those with a low reading age.
In fact there are lots of categories of people who'll struggle to read practical information and advice about diabetes, or any health condition, including people who've not learned to read, people with dyslexia, people whose first language isn't English, people with learning difficulties etc. Even people with good reading skills may well struggle to read something if it's not written clearly.
A large proportion of our constituency are people from backgrounds who may not be equipped to access information easily - for this reason we have information in web and print formats, and in a variety of languages and alternative formats (eg audio for those with visual problems). Diabetes is more common among South Asian people where English may not be the first language so info is available in a variety of Asian languages, it's also more common among people with learning difficulties and so we have pictorial information available.
In 2004 an article on the BBC's news website reported that "Diabetes websites (are) too complicated". The analysis of several diabetes health websites included ours, although they called us the British Diabetic Association, and found that you'd need a reading age of about 15 to comprehend our site despite the fact that the average reading age was apparently nine years old.
Martin Robbins wondered if there comes a point where people communicating information can't really take responsibility for a lack in anyone's education - true enough we can't, but in our case we are 'the charity for people with diabetes' and have set ourselves the goal of getting our information to as many people with diabetes as possible.
There are plenty of people who have poor literacy though. According to the National Literacy Trust (2010) 'One in six people in the UK struggle with literacy. This means their literacy is below the level expected of an eleven year old' - that data comes from the 2003 DfES 'Skills for Life' report. The NLT also notes that 'the Leitch Review, found that more than five million adults lack functional literacy, the level needed to get by in life and at work.'
The National Patient Safety Agency (NPSA) has produced a number of booklets highlighting how the design of a variety of medical devices (including labelling) can affect how easy it is to follow instructions or understand what needs to be done http://www.nrls.npsa.nhs.uk/resources/collections/design-for-patient-safety/ - scroll down to see their suggestions for medicine labels (PDF).
Jama D and Dugdale G (2010) Literacy: State of the Nation: a picture of literacy in the UK today. National Literacy Trust.
http://www.literacytrust.org.uk/assets/0000/3816/FINAL_Literacy_State_of_the_Nation_-_30_March_2010.pdf
This may also be of interest:
Paasche-Orlow MK, Parker Rm, Gazmarian JA et al (2005) The prevalence of limited health literacy. Journal of General Internal Medicine 19: 1228-1239.
http://www.ncbi.nlm.nih.gov/pmc/articles/PMC1490053/pdf/jgi_40245.pdf
See also
Following this tweet
@mjrobbins RT @fivethirtyeight Words like 'earthquake' and 'challenge' elitist as have 7+ letters - CNN "expert". http://bit.ly/cUfOZg
there's been a bit of discussion on Twitter about reading ability and literacy. I posted that I believed something like a fifth of adults had literacy problems but Ed Yong challenged that 'problem' isn't necessarily an appropriate category description and that it's more reasonable to view it as a young reading age and difficulty with certain technical words. Certainly I'd agree that I don't want to apply pejorative categories to people but I think there are people who have more serious difficulties with reading and comprehension, more serious than those with a low reading age.
In fact there are lots of categories of people who'll struggle to read practical information and advice about diabetes, or any health condition, including people who've not learned to read, people with dyslexia, people whose first language isn't English, people with learning difficulties etc. Even people with good reading skills may well struggle to read something if it's not written clearly.
A large proportion of our constituency are people from backgrounds who may not be equipped to access information easily - for this reason we have information in web and print formats, and in a variety of languages and alternative formats (eg audio for those with visual problems). Diabetes is more common among South Asian people where English may not be the first language so info is available in a variety of Asian languages, it's also more common among people with learning difficulties and so we have pictorial information available.
In 2004 an article on the BBC's news website reported that "Diabetes websites (are) too complicated". The analysis of several diabetes health websites included ours, although they called us the British Diabetic Association, and found that you'd need a reading age of about 15 to comprehend our site despite the fact that the average reading age was apparently nine years old.
Martin Robbins wondered if there comes a point where people communicating information can't really take responsibility for a lack in anyone's education - true enough we can't, but in our case we are 'the charity for people with diabetes' and have set ourselves the goal of getting our information to as many people with diabetes as possible.
There are plenty of people who have poor literacy though. According to the National Literacy Trust (2010) 'One in six people in the UK struggle with literacy. This means their literacy is below the level expected of an eleven year old' - that data comes from the 2003 DfES 'Skills for Life' report. The NLT also notes that 'the Leitch Review, found that more than five million adults lack functional literacy, the level needed to get by in life and at work.'
The National Patient Safety Agency (NPSA) has produced a number of booklets highlighting how the design of a variety of medical devices (including labelling) can affect how easy it is to follow instructions or understand what needs to be done http://www.nrls.npsa.nhs.uk/resources/collections/design-for-patient-safety/ - scroll down to see their suggestions for medicine labels (PDF).
Jama D and Dugdale G (2010) Literacy: State of the Nation: a picture of literacy in the UK today. National Literacy Trust.
http://www.literacytrust.org.uk/assets/0000/3816/FINAL_Literacy_State_of_the_Nation_-_30_March_2010.pdf
This may also be of interest:
Paasche-Orlow MK, Parker Rm, Gazmarian JA et al (2005) The prevalence of limited health literacy. Journal of General Internal Medicine 19: 1228-1239.
http://www.ncbi.nlm.nih.gov/pmc/articles/PMC1490053/pdf/jgi_40245.pdf
See also
- National Forum on Information Literacy (US) http://www.infolit.org/index.html
- Patient Information Literacy (UK) http://www.informationliteracy.org.uk/Resources_By_Theme/Patient_il.aspx
- CILIP CSG Information Literacy Group (UK) http://www.informationliteracy.org.uk/CILIP_CSG_IL.aspx - I don't think it's restricted to health
- Patient Information Forum (PIF) on health literacy http://www.pifonline.org.uk/themes/health-literacy/ (health literacy isn't the same as general literacy but it's often related).
Stempra event: Promoting non peer reviewed science?
Disclaimer: I work for Diabetes UK and UCL; these views are my own.
Recently I attended an event, on 'Promoting non peer reviewed science' about research that hasn't been through the whole publication and peer review process, hosted by Stempra (science, technology, engineering and medicine public relations association) which was held in a comfortable upstairs room in a London pub - there were about 20 of us in attendance. I took along my laptop to make some notes and here they are.
Lucy Harper led the discussion - she's the Communications Manager at 'SfAM', the Society for Applied Microbiology and she edits their members' magazine 'Microbiologist'. Each year, like many similar organisations, their society has professional meetings. Such meetings often involve presentations of preliminary data and the publicity given to these meetings means that journalists may well be present in the audience. What's the appropriate thing to do here? Forewarn the speakers and find out if any are happy to be interviewed, and mention that other people may be tweeting or does this run the risk that the speakers will make changes (ie remove bits) to their presentation. Scientists can be (not unreasonably) wary of publicising preliminary data - there's the fear that future publication might be harder if the content has been widely shared in advance (see Ingelfinger rule, below) but also the concern that sharing data via non-published means could result in others 'scooping' them. One scientist that Lucy spoke to wasn't so concerned about potential risks to future publications, but was worried that a larger and better financed research team might take advantage of their data.
An audience member commented that even if Twitter or news media were taken out of the equation this fear of being scooped didn't really make sense since the potential scoopers were likely in the audience and hearing from the presenter directly, although the reach of Twitter is obviously much larger than just the room. I'm aware of the contrast with a few scientists (Peter Murray-Rust, Cameron Neylon, Jean-Claude Bradley), all of whom have spoken at either Science Blogging 2008 or Science Online 2009 (in London, Science Online 2010 is in September) on making their results available in real-time by posting them on the web and getting immediate feedback from comments. I'm not sure if chemistry / biophysics is less amenable to being scooped by other teams than other fields making this a 'safer' thing to do, let alone a helpful and completely transparent way to conduct the research that is paid for by the public (through the research councils).
On the concept of further reach I was reminded of similar comments made around the time that Daniel MacArthur tweeted freely from a genetics conference while journalist delegates had been required to sign an agreement on how they would use conference material. In this case, the conference subsequently changed its regulations so that anyone - mainstream media, bloggers or microbloggers (those on Twitter etc) - would be aked to sign an agreement in advance. I've collected quite a few of the blog posts relating to this (http://brodiesnotes.blogspot.com/2010/02/curated-posts-liveblogging-science.html), as part of a wider-themed post myself on the issue of tweeting from scientific conferences. My particular interest in this is tweeting from medical health conferences - Diabetes UK (where I work) has an annual professional conference at which new data is presented, not always published / peer-reviewed of course, and I expect that with each passing year there may be more people tweeting from the audience. I don't think we, or other charities in a similar position, can reasonably expect to prevent people from doing this but I don't think it hurts to have some ground rules (well, suggestions) given that this info goes into the public domain and may be picked up by someone who isn't aware of the full context. I'm not sure I agree with putting conferences under Chatham House Rules although I acknowledge the argument that it might help scientists feel more comfortable in sharing more info.
Re context: this point was highlighted by one of Lucy's scientists as well - the quality of data is likely to be deprecated in a tweet and can easily be misinterpreted by the 140 characters limit, with speculation and caution from the speaker turning into 'fact'.
Ingelfinger rule"The policy of considering a manuscript for publication only if its substance has not been submitted or reported elsewhere. This policy was promulgated in 1969 by Franz J. Ingelfinger, then the editor of The New England Journal of Medicine. The aim of the Ingelfinger rule was to protect the Journal from publishing material that had already been published and thus had lost its originality." Source: http://www.medterms.com/script/main/art.asp?articlekey=13488
See also: http://en.wikipedia.org/wiki/Scientific_misconduct#Responsibility_of_authors_and_of_coauthors
and Ingelfinger Over-Ruled: The Role of the Web in the Future of Refereed Medical Journal Publishing (2000)
http://cogprints.org/1703/1/harnad00.lancet.htm
If the Ingelfinger rule was extended so that any mention of data precluded its publication then this might well be a case of the communications movement taking a step backwards, limiting the sharing of information. If something has been presented as a poster at a conference this shouldn't prevent it from being published in a journal and this is the approach that SfAM takes.
I don't know what the percentage of new or preliminary data is presented at conferences - obviously it's not 'old' info, but some stuff is surely in press and so there must be a continuum of data from the very fresh and unexamined to much more pored-over stuff. Nonetheless a lot of what gets reported from scientific conferences hasn't been through the full process of peer review, either the review process to get into a journal publication or the 'post-marketing' scrutiny once other scientists get their mitts on it - an example of post-publishing scrutiny might be the Rapid Responses from the BMJ, although these comments aren't peer-reviewed either of course.
My job at Diabetes UK involves me answering public enquiries on the science of diabetes and this can include results publicised from our Annual Professional Conference. If something preliminary has been mentioned in the papers it may take some time before a formal publication is available so this means that the status of the information is 'lower' than something which has been through the process. That's a bit of a simplification as the peer-review process isn't perfect and just because something is published doesn't mean that it's 'right' - but you know what I mean ;)
Part of my reason for showing such an interest in the publicising of data, perhaps via Twitter, was my concern that someone following the conference hashtag might read more into a tweet than they should - I don't particularly enjoy having to explain to someone that a piece of early stage research has somehow been translated as being further forward and more certain than it is, particularly if it's work that we've funded.
I've previously written about my thoughts on stories in the media and how they are understood by those reading them - this is my experience of over six years responding to enquirers calls and emails about something they've read in the papers. I've quoted it below because the rest of the blog post isn't as relevant here.
"Firstly, some observations of my own. Often a story is perfectly clearly written but the headline lets it down. Or there's a throwaway brief para which contains an otherwise minor error but in context gives the wrong impression. I don't think that view is going to startle anyone.
What you *might* be less aware of is how wrongly people can apprehend, or remember, a story they've read in the newspapers - although if you think about it, not really that much of a surprise. Probably someone's done some research on this but I confess I am ignorant of it.
People have rung in wanting to know about something they read "last month in the papers", only for me to find that it was actually *months* ago, my record for the longest gap is three and a half years. Memories - not so reliable."
Source: http://brodiesnotes.blogspot.com/2010/04/healthy-journalism-challenges-and.html
I'm not entirely sure how the press release world works - I know we put them out, but presumably the researchers' host university will put out releases too and, if the research is at the point of being published then journals might pitch in too. Hopefully the universe doesn't end up with three separate releases on the same topic but for all I know it might. Only in the case of research-about-to-be-published has it been through a peer review process.
It seems that most of us in the room could live with non-peer-reviewed information being publicised but only as long as the preliminary nature of the work is made clear.
I also thought about other ways in which preliminary work might be publicised. Our charity, and I'm sure other charities too, will write articles which include progress reports for the work that we fund. Inherent in its 'progress report' nature is the implication that this work is at an early stage, and it's entirely possible that as the work progresses it will 'change direction'. Talking about the research that we fund is an essential part of what we do - people raise money for us and they have a right to know how that money is being spent and what is happening. We do also want to tell people a little about the process of research, for example that it takes a long time and that each project generally looks at one small aspect of research. Every charity has a responsibility to publish basic information about the breakdown of spending costs but almost all take this a step further and use this as an opportunity to talk about the research itself, the people undertaking it and any collaborations between institutions. The resulting document is not only a fundraising tool but it lets everyone in the charity know what work is being done.
Someone made the interesting comment that even if the data is at the point where it hasn't been peer-reviewed, the application form for the project that generated the data has been peer-reviewed. While that's true I'm not sure how satisfactory that is. It was also pointed out that the Government's reports aren't peer-reviewed, though they do go through an editing process. Similarly conference abstracts go through a version of peer review, beyond merely editorial control.
Even if journalists aren't present at a conference the output of those tweeting from it (in a delegate capacity) is part of the public record and may well be being followed by journalists not 'in the room' who might spot a story and follow it up.
In addition to material not being peer reviewed we discussed whether members of the public are aware that the concept of peer review might be used as a benchmark of quality (except in the case of homeopathy which seems to be a fine example of peer review failing to pick up and winnow out nonsense, also Andrew Wakefield's paper). There's a useful document from Sense About Science which explains peer review to a non-specialist audience (http://www.senseaboutscience.org.uk/index.php/site/project/30, see also http://www.senseaboutscience.org.uk/index.php/site/project/29/). Peer review is often criticised as something that's subjective / biased and a very imperfect system although it's 'the best we've got' at the moment, perhaps.
A couple of final thoughts which didn't quite fit anywhere else...
How should an opinion from an esteemed person at a conference be reported, if at all. It's all very well with the 'nullius in verba' (the Royal Society's motto which means 'on the word of no-one' or 'take nobody's word for it' - ie don't be overly impressed by authority, just because someone important says something it doesn't mean that it's true) but what happens if someone comes out with a great soundbite? If people are speaking more colloquially at a conference (and this is understood by those in the room but not necessarily by those outside) then there's a risk that it will get mistranslated. In the last six years working at Diabetes UK I've read plenty of news articles where a scientist is quoted as saying that there will be a cure for diabetes within the next five years - not unexpectedly people ring us up wanting to know what this is all about. If I heard someone say this at a conference to be honest I'd simply ignore it, I wouldn't even say "so and so says...".
Finally - science blogs. The blogs themselves are in the most part not peer-reviewed, although I think those hosted at the Research Blogging platform restrict themselves to writing about peer-reviewed research and many other blog platforms host blogs that go through an editorial process.
This blog post hasn't been peer reviewed though I did send it to Lucy Harper, the speaker, to check that I'd not misunderstood, misinterpreted or misrepresented anything :)
Recently I attended an event, on 'Promoting non peer reviewed science' about research that hasn't been through the whole publication and peer review process, hosted by Stempra (science, technology, engineering and medicine public relations association) which was held in a comfortable upstairs room in a London pub - there were about 20 of us in attendance. I took along my laptop to make some notes and here they are.
Lucy Harper led the discussion - she's the Communications Manager at 'SfAM', the Society for Applied Microbiology and she edits their members' magazine 'Microbiologist'. Each year, like many similar organisations, their society has professional meetings. Such meetings often involve presentations of preliminary data and the publicity given to these meetings means that journalists may well be present in the audience. What's the appropriate thing to do here? Forewarn the speakers and find out if any are happy to be interviewed, and mention that other people may be tweeting or does this run the risk that the speakers will make changes (ie remove bits) to their presentation. Scientists can be (not unreasonably) wary of publicising preliminary data - there's the fear that future publication might be harder if the content has been widely shared in advance (see Ingelfinger rule, below) but also the concern that sharing data via non-published means could result in others 'scooping' them. One scientist that Lucy spoke to wasn't so concerned about potential risks to future publications, but was worried that a larger and better financed research team might take advantage of their data.
An audience member commented that even if Twitter or news media were taken out of the equation this fear of being scooped didn't really make sense since the potential scoopers were likely in the audience and hearing from the presenter directly, although the reach of Twitter is obviously much larger than just the room. I'm aware of the contrast with a few scientists (Peter Murray-Rust, Cameron Neylon, Jean-Claude Bradley), all of whom have spoken at either Science Blogging 2008 or Science Online 2009 (in London, Science Online 2010 is in September) on making their results available in real-time by posting them on the web and getting immediate feedback from comments. I'm not sure if chemistry / biophysics is less amenable to being scooped by other teams than other fields making this a 'safer' thing to do, let alone a helpful and completely transparent way to conduct the research that is paid for by the public (through the research councils).
On the concept of further reach I was reminded of similar comments made around the time that Daniel MacArthur tweeted freely from a genetics conference while journalist delegates had been required to sign an agreement on how they would use conference material. In this case, the conference subsequently changed its regulations so that anyone - mainstream media, bloggers or microbloggers (those on Twitter etc) - would be aked to sign an agreement in advance. I've collected quite a few of the blog posts relating to this (http://brodiesnotes.blogspot.com/2010/02/curated-posts-liveblogging-science.html), as part of a wider-themed post myself on the issue of tweeting from scientific conferences. My particular interest in this is tweeting from medical health conferences - Diabetes UK (where I work) has an annual professional conference at which new data is presented, not always published / peer-reviewed of course, and I expect that with each passing year there may be more people tweeting from the audience. I don't think we, or other charities in a similar position, can reasonably expect to prevent people from doing this but I don't think it hurts to have some ground rules (well, suggestions) given that this info goes into the public domain and may be picked up by someone who isn't aware of the full context. I'm not sure I agree with putting conferences under Chatham House Rules although I acknowledge the argument that it might help scientists feel more comfortable in sharing more info.
Re context: this point was highlighted by one of Lucy's scientists as well - the quality of data is likely to be deprecated in a tweet and can easily be misinterpreted by the 140 characters limit, with speculation and caution from the speaker turning into 'fact'.
Ingelfinger rule"The policy of considering a manuscript for publication only if its substance has not been submitted or reported elsewhere. This policy was promulgated in 1969 by Franz J. Ingelfinger, then the editor of The New England Journal of Medicine. The aim of the Ingelfinger rule was to protect the Journal from publishing material that had already been published and thus had lost its originality." Source: http://www.medterms.com/script/main/art.asp?articlekey=13488
See also: http://en.wikipedia.org/wiki/Scientific_misconduct#Responsibility_of_authors_and_of_coauthors
and Ingelfinger Over-Ruled: The Role of the Web in the Future of Refereed Medical Journal Publishing (2000)
http://cogprints.org/1703/1/harnad00.lancet.htm
If the Ingelfinger rule was extended so that any mention of data precluded its publication then this might well be a case of the communications movement taking a step backwards, limiting the sharing of information. If something has been presented as a poster at a conference this shouldn't prevent it from being published in a journal and this is the approach that SfAM takes.
I don't know what the percentage of new or preliminary data is presented at conferences - obviously it's not 'old' info, but some stuff is surely in press and so there must be a continuum of data from the very fresh and unexamined to much more pored-over stuff. Nonetheless a lot of what gets reported from scientific conferences hasn't been through the full process of peer review, either the review process to get into a journal publication or the 'post-marketing' scrutiny once other scientists get their mitts on it - an example of post-publishing scrutiny might be the Rapid Responses from the BMJ, although these comments aren't peer-reviewed either of course.
My job at Diabetes UK involves me answering public enquiries on the science of diabetes and this can include results publicised from our Annual Professional Conference. If something preliminary has been mentioned in the papers it may take some time before a formal publication is available so this means that the status of the information is 'lower' than something which has been through the process. That's a bit of a simplification as the peer-review process isn't perfect and just because something is published doesn't mean that it's 'right' - but you know what I mean ;)
Part of my reason for showing such an interest in the publicising of data, perhaps via Twitter, was my concern that someone following the conference hashtag might read more into a tweet than they should - I don't particularly enjoy having to explain to someone that a piece of early stage research has somehow been translated as being further forward and more certain than it is, particularly if it's work that we've funded.
I've previously written about my thoughts on stories in the media and how they are understood by those reading them - this is my experience of over six years responding to enquirers calls and emails about something they've read in the papers. I've quoted it below because the rest of the blog post isn't as relevant here.
"Firstly, some observations of my own. Often a story is perfectly clearly written but the headline lets it down. Or there's a throwaway brief para which contains an otherwise minor error but in context gives the wrong impression. I don't think that view is going to startle anyone.
What you *might* be less aware of is how wrongly people can apprehend, or remember, a story they've read in the newspapers - although if you think about it, not really that much of a surprise. Probably someone's done some research on this but I confess I am ignorant of it.
People have rung in wanting to know about something they read "last month in the papers", only for me to find that it was actually *months* ago, my record for the longest gap is three and a half years. Memories - not so reliable."
Source: http://brodiesnotes.blogspot.com/2010/04/healthy-journalism-challenges-and.html
I'm not entirely sure how the press release world works - I know we put them out, but presumably the researchers' host university will put out releases too and, if the research is at the point of being published then journals might pitch in too. Hopefully the universe doesn't end up with three separate releases on the same topic but for all I know it might. Only in the case of research-about-to-be-published has it been through a peer review process.
It seems that most of us in the room could live with non-peer-reviewed information being publicised but only as long as the preliminary nature of the work is made clear.
I also thought about other ways in which preliminary work might be publicised. Our charity, and I'm sure other charities too, will write articles which include progress reports for the work that we fund. Inherent in its 'progress report' nature is the implication that this work is at an early stage, and it's entirely possible that as the work progresses it will 'change direction'. Talking about the research that we fund is an essential part of what we do - people raise money for us and they have a right to know how that money is being spent and what is happening. We do also want to tell people a little about the process of research, for example that it takes a long time and that each project generally looks at one small aspect of research. Every charity has a responsibility to publish basic information about the breakdown of spending costs but almost all take this a step further and use this as an opportunity to talk about the research itself, the people undertaking it and any collaborations between institutions. The resulting document is not only a fundraising tool but it lets everyone in the charity know what work is being done.
Someone made the interesting comment that even if the data is at the point where it hasn't been peer-reviewed, the application form for the project that generated the data has been peer-reviewed. While that's true I'm not sure how satisfactory that is. It was also pointed out that the Government's reports aren't peer-reviewed, though they do go through an editing process. Similarly conference abstracts go through a version of peer review, beyond merely editorial control.
Even if journalists aren't present at a conference the output of those tweeting from it (in a delegate capacity) is part of the public record and may well be being followed by journalists not 'in the room' who might spot a story and follow it up.
In addition to material not being peer reviewed we discussed whether members of the public are aware that the concept of peer review might be used as a benchmark of quality (except in the case of homeopathy which seems to be a fine example of peer review failing to pick up and winnow out nonsense, also Andrew Wakefield's paper). There's a useful document from Sense About Science which explains peer review to a non-specialist audience (http://www.senseaboutscience.org.uk/index.php/site/project/30, see also http://www.senseaboutscience.org.uk/index.php/site/project/29/). Peer review is often criticised as something that's subjective / biased and a very imperfect system although it's 'the best we've got' at the moment, perhaps.
A couple of final thoughts which didn't quite fit anywhere else...
How should an opinion from an esteemed person at a conference be reported, if at all. It's all very well with the 'nullius in verba' (the Royal Society's motto which means 'on the word of no-one' or 'take nobody's word for it' - ie don't be overly impressed by authority, just because someone important says something it doesn't mean that it's true) but what happens if someone comes out with a great soundbite? If people are speaking more colloquially at a conference (and this is understood by those in the room but not necessarily by those outside) then there's a risk that it will get mistranslated. In the last six years working at Diabetes UK I've read plenty of news articles where a scientist is quoted as saying that there will be a cure for diabetes within the next five years - not unexpectedly people ring us up wanting to know what this is all about. If I heard someone say this at a conference to be honest I'd simply ignore it, I wouldn't even say "so and so says...".
Finally - science blogs. The blogs themselves are in the most part not peer-reviewed, although I think those hosted at the Research Blogging platform restrict themselves to writing about peer-reviewed research and many other blog platforms host blogs that go through an editorial process.
This blog post hasn't been peer reviewed though I did send it to Lucy Harper, the speaker, to check that I'd not misunderstood, misinterpreted or misrepresented anything :)
Tuesday, 15 June 2010
List of 'Ning: Science and Society' organisations - potential science communication opportunities
This is a reposting of an earlier post, but with better formatting.
Gillian Pepper collected this list and clearly put a lot of work into it. I harvested it from her Science and Society Ning page (Ning changed its platform in such a way that a lot of free networks closed and I didn't want to lose this resource).
I went in and copied the source code (View / Page Source in FireFox) and copied it into a blog page (using the edit html tab rather than compose) to keep it safe - it lives here - but on that page I didn't alter its formatting (which was mildly less compatible with Blogger). I'm leaving that original page in its 'historic setting', but have tweaked this version to make it a bit more visually helpful.
Eventually I'll insert individual organisations into the Science Communicators Vacancies Pages page but wanted to keep this as an individual page to reflect the work that Gillian did.
---------------------------
Gillian Pepper collected this list and clearly put a lot of work into it. I harvested it from her Science and Society Ning page (Ning changed its platform in such a way that a lot of free networks closed and I didn't want to lose this resource).
I went in and copied the source code (View / Page Source in FireFox) and copied it into a blog page (using the edit html tab rather than compose) to keep it safe - it lives here - but on that page I didn't alter its formatting (which was mildly less compatible with Blogger). I'm leaving that original page in its 'historic setting', but have tweaked this version to make it a bit more visually helpful.
Eventually I'll insert individual organisations into the Science Communicators Vacancies Pages page but wanted to keep this as an individual page to reflect the work that Gillian did.
---------------------------
Science and Society Directory
ACADEMIC
GOVERNMENT AND PARLIAMENT
There are a number of relevant Government departments, agencies and quangoes and Parliamentary bodies and organisations:
The learned societies are listed below in alphabetical order:
Research units:
- The Institute for Science in Society - at Nottingham University
- The Science Policy Research Unit - at Sussex University
- Policy Research in Science, Engineering and Technology - at Manchester University
- Science Communication Unit - at the University of the West of England.
- The Evidence for Policy in Practice Coordinating Centre - runs an Evidence Library and an MSc in Evidence for Public Policy and Practice.
Courses:
- Birkbeck University of London - offers a diploma in Science Communication
- The University of Bath - does an MSc in Science, Culture and Communication
- Cardiff University - runs a relatively new course in Science, Media and Communication
- In addition, The University of Glamorgan runs an established course in Communicating Science and also Science Shops that undertake communication activities in local communities.
- Dublin City University - also offers an MSc in Science Communication.
- Imperial College London - runs a Science Communication Group and offers taught courses in Science Communication and Science Media Production.
- The University of Manchester MSc in History of Science, Technology and Medicine includes two units focused on science communication.
- University College London offers relevant courses in its Department for Science and Technology Studies
- University of Chester has a Centre for Science Communication offering an MSc, postgraduate diplomas and a postgraduate certificate in Science Communiction.
- University of the West of England - runs a MSc and also offers a five day masterclass in science commuication.
- The American Association for the Advancement of Science produces, among other things, Science Magazine, and Science Update Radio.
- The Association of British Science Writers helps those who write about science and technology, and aims to improve the standard of science journalism in the UK. They also list a number of science journalism competitions on the website.
- The British Science Association s the well-known organisation responsible for events such as National Science and Engineering Week and the annual British Science Festival.
- The British Neuroscience Association runs a science writing prize. The National Brain-Science Writing Prize. Winners have their articles published in the BNA Bulletin.
- The BBC - Specialist Factual and Science and Nature are the two main departments of the BBC that produce the science-based programmes and web content with which we are all familiar.
- BBC Focus, the Sky at Night and Wildlife Magazines are some of the many Origin Publishing magazines produced under the BBC banner.
- The Daily Telegraph also runs a science writing prize - winners gain £1000, a work placement at the Telegraph and have their articles printed in the paper.
- Nature Publishing Group produces a wide range of journals as well as a number of web-based resources.
- New Scientist Magazine should need no introduction.
- The Beacons for Public Engagement are a number of RCUK, HEFCE and Wellcome - funded collaborative groups, comprised of university departments, museums, and voluntary science communication initiatives, that actively communicate science in the UK regions.
- Pulse Project is a science communication site, which offers all its videos for free and has guest bloggers in the field.
- ScienceBase is a Science News site produced by science writer David Bradley
- The Science Media Centre is an independent press centre working to improve the accuracy of science stories produced by the national media.
- Sense About Science promotes good science and evidence for the public.
- Wildscreen Festival
- Association for Astronomy Education
- The Association for Science Education
- Association of Charity Independent Examiners
- College of Teachers
- Council for Industry and Higher Education
- Institute of Health Promotion and Education
- Association for Learning Technology
- Association of Teachers of Mathematics
- Educational Centres Association
- The Learning Grid
- Society for Research into Higher Education
- Clifton Scientific Trust
- Higher Education Funding Council for England and Higher Education Funding Council for Wales distribute public money for teaching and research to universities and colleges in their respective regions.
- The UK Research Councils (RCUK) office, is the collective centre for seven bodies: The Arts and Humanities Research Council (AHRC), the Biotechnology and Biological Sciences Research Council (BBSRC), the Economic and Social Research Council (ESRC), the Engineering and Physical Sciences Research Council (EPSRC), the Medical Research Council (MRC), the Natural Environment Research Council (NERC) and the relatively new Science and Technology Facilities Council (STFC).
- Sciencewise
- The British Council - science sector
- The British Heart Foundation
- The Leverhulme Trust
- The Royal Society
- The Wellcome Trust
GOVERNMENT AND PARLIAMENT
There are a number of relevant Government departments, agencies and quangoes and Parliamentary bodies and organisations:
- Commonwealth Agricultural Bureaux International (CABI) is a not-for-profit, intergovernmental organisation that applies scientific solutions to environmental and agricultural problems.
- Council for Science and Technology is a Government advisory body for science policy issues.
- Department for Children Schools and Families
- Department for Environment Food and Rural Affairs
- Department of Health
- Department for Business, Innovation and Skills
- Department for Transport
- E-Government Unit
- Foresight
- The Higher Education Funding Council for England
- The Higher Education Funding Council for Wales
- The Human Fertilisation and Embryology Authority
- National Endowment for Science Technology and the Arts
- Technology Strategy Board
- Parliamentary Office of Science and Technology
- Parliamentary and Scientific Committee
The learned societies are listed below in alphabetical order:
- Academy of Medical Sciences Academy of Social Sciences Agricultural Economics SocietyAnatomical Society of Great Britain and Ireland Association of Applied Biologists Association of the British Pharmaceutical Industry
- Association of Clinical Biochemistry
- Association of Clinical Pathologists
- Association of Independent Research and Technology Organisations Association of Marine Scientific Industries
- Association of Medical Research Charities
- Biochemical Society
- Biosciences Federation
- Botanical Society of the British Isles
- Bristol Naturalists Society
- British Academy
- British Association for Psychopharmacology
- British Computer Society
- British Crop Protection Council
- British Dental Association
- British Ecological Society
- British Entomological and Natural History Society
- British Grassland Society
- British Herpetological Society
- British Interplanetary Society
- British Medical Ultrasound Society
- British Naturalists Association
- British Nutrition Foundation
- British Pharmacological Society
- British Pteridological Society
- British Society for Antimicrobial Chemotherapy
- British Society for Cell Biology
- British Society for Geomorphology
- British Society for Medical Mycology
- British Society for Plant Pathology
- British Society for Rheology
- British Society for Rheumatology
- British Society for the History of Mathematics
- British Society for the History of Science
- British Society of Audiology
- British Society of Toxicological Pathologists
- British Sociological Association
- British Transplantation Society
- British Veterinary Association
- Challenger Society for Marine Science
- Chartered Institute of Architectural Technologists
- Chartered Institution of Water and Environmental Management
- Consortium of Research Libraries
- Energy Institute
- Ergonomics Society
- Fauna & Flora International
- Fisheries Society of the British Isles
- Freshwater Biological Association
- Galton Institute
- Gemological Association
- Geographical Association
- Geological Society
- Health Professions Council
- Health Protection Agency
- Institution of Agricultural Engineers
- Institute of Conservation
- Institute of Marine Engineering, Science and Technology
- Institute for the Management of Information Systems
- Institute of Acoustics
- Institute of Automotive Engineer Assessors
- Institute of Biology
- Institute of Biomedical Science
- Institute of Cast Metals Engineers
- Institute of Corrosion
- Institute of Ecotechnics
- Institution of Environmental Sciences
- Institute of Fisheries Management
- Institute of Food Science & Technology
- Institute of Healthcare Management
- Institute of Highway Incorporated Engineers
- Institute of Horticulture
- Institute of Materials, Minerals and Mining
- Institute of Musical Instrument Technology
- Institute of Physics
- Institute of Physics and Engineering in Medicine
- Institute of Psychoanalysis
- Institute of Science Technology
- Institute of Structural Engineers
- Institute of Trichologists
- Institute for Animal Health
- Institution of Chemical Engineers
- Institution of Civil Engineers
- Institution of Electronics
- Institution of Engineering and Technology
- Institution of Engineering Designers
- Institution of Environmental Sciences
- Institution of Gas Engineers and Managers
- Institution of Lighting Engineers
- Institution of Mechanical Engineers
- Institution of Structural Engineers
- Intellectual Property Institute
- International Bee Research Association
- International Federation of Hydrographic Societies
- International Glaciological Society
- International Institute for Environment and Development
- Linnean Society of London
- List and Index Society
- London Mathematical Society
- London Metropolitan Polymer Centre
- London Topographical Society
- Marine Conservation Society
- Market Research Society
- Mineralogical Society
- Modern Humanities Research Association
- National Bursars' Association
- National Osteoporosis Society
- National Physical Laboratory
- Natural England
- Nautical Institute
- Nutrition Society
- Operational Research Society
- Palaeontographical Society
- Palaeontological Association
- Pathological Society
- Physiological Society
- Quekett Microscopical Club
- Remote Sensing and Photogrammetry Society
- Research and Development Society
- Royal Academy of Arts
- Royal Academy of Engineering
- Royal Aeronautical Society
- Royal Agricultural Society
- Royal Archaeological Institute
- Royal Astronomical Society
- Royal College of Anaesthetists
- Royal College of General Practitioners
- Royal College of Midwives Trust
- Royal College of Obstetricians and Gynaecologists
- Royal College of Ophthalmologists
- Royal College of Pathologists
- Royal College of Physicians
- Royal College of Psychiatrists
- Royal College of Surgeons of England
- Royal College of Veterinary Surgeons
- Royal Entomological Society
- Royal Forestry Society
- Royal Geographical Society
- Royal Historical Society
- Royal Horticultural Society
- Royal Institute of Navigation
- Royal Institute of Philosophy
- Royal Institute of Public Health
- Royal Institution of Great Britain
- Royal Meteorological Society
- Royal Microscopical Society
- Royal Society for the Promotion of Health
- Royal Society of Medicine
- Royal Society of Tropical Medicine and Hygiene
- Royal Society of Wildlife Trusts
- Royal Statistical Society
- Royal Welsh Agricultural Society
- Science Engineering and Manufacturing Technologies Alliance
- Science Council
- Scientific Instrument Society
- Scottish Association for Marine Science
- Society for Applied Microbiology
- Society for Computers and Law
- Society for Endocrinology
- Society for General Microbiology
- Society for Psychical Research
- Society for Underwater Technology
- Society of Archivists
- Society of Chemical Industry
- Society of Chiropodists and Podiatrists
- Society of Cosmetic Scientists
- Society of Environmental Engineers
- Society of Food Hygiene and Technology
- Society of Indexers
- Society of Operations Engineers
- Society of Radiographers
- Solar Energy Society
- Strategic Planning Society
- Textile Institute
- The British Psychological Society
- The Chartered Institute of Library and Information Professionals
- The Engineering and Technology Board
- The Environment Council
- The Marine Biological Association of the UK
- The Royal Society
- The Royal Society of Chemistry
- The Royal Statistical Society
- The Worshipful Society of Apothecaries of London
- Tropical Biology Association
- UK Centre for Economic and Environmental Development Universities Federation for Animal Welfare
- Wildlife and Countryside Link
- Blue Planet Aquarium
- Bristol Zoo Gardens
- The British Interactive Group (BIG) is a non-profit organisation for those involved in interactive science communication activities and hands-on education projects in the UK. The BIG directory contains a list of science museums and centres in the UK.
- Centre for Life is a unique combination of biomedical research, clinical facilities, ethics, education and public engagement located on a single site in the centre of Newcastle. It houses a 4,500 sqm exhibition, a suite of teaching labs and research onsite includes genetics and stem cell research.
- Chester Zoo
- Ecsite-uk is a UK Network of Science Centres and Museums, representing 50+ science centres in the UK as well as aquariums, gardens and zoos.
- The Dana Centre is a purpose-built venue in London It is a place for adults to take part in exciting, informative and innovative debates about contemporary science, technology and culture.
- The Grant Museum of Zoology.
- @Bristol
- Bristol Natural History Consortium is a unique alliance between At-Bristol, Avon Wildlife Trust, BBC Natural History Unit, Bristol City Council, Bristol Zoo Gardens, University of Bristol, University of the West of England, Wildscreen and WWF-UK. The Consortium reflects Bristol’s reputation as a leading centre for the understanding and appreciation of the natural world.
- London Aquarium
- Kew Gardens
- Think Tank Birmingham
- Centre of the Cell
- London Zoo
- National Maritime Museum
- Museums Association
- National Museums of Science and Industry (NMSI)
- Natural History Museum
- Sea Life centres can be found in cities across Europe.
- Techniquest science centres can be found in a number of locations in Wales.
- Whipsnade Zoo
- Agricultural Development and Advisory Service is an independent science based rural and environmental policy consultancy.
- The Centre for Evidence-Based Conservation was established in 2003 with the goal of supporting decision making in conservation and environmental management through the production and dissemination of systematic reviews on the effectiveness of management and policy interventions. Relevant conservation can also be found on a seperate website - conservationevidence.com
- The Parliamentary and Scientific Committee is an Associate Parliamentary Group that produces the Science in Parliament Journal.
- The Foundation for Science and Technology provides a neutral platform for debate of policy issues with a science angle. The Foundation organises discussions and produces a journal.
- Newton's Apple is a neutral, non-partisan charity working at the interface between science and policy.
- People Science & Policy is an independent public policy consultancy that specialises in science and society issues
- Prospect is and independent union representing those working in science, technology and related professions.
- Understanding Animal Research aims to achieve understanding and acceptance of the need for humane animal research in the UK, by maintaining and building informed public support and a favourable policy climate for animal research.
- The RAND Cooporation is an international non-profit corporation that aims to improve policy and decision-making by providing a research and analysis sevice.
- The Science Policy Support Group operated between 1986-2003. SPSG was set up by the ESRC, with the intial support of the other Research Councils, to organise programmes of research and information on issues of science and technology policy identified as of strategic importance.
- The Science and Development Network is an organisation which aims to provide reliable science and technology information for the developing world.
- The Royal Society is also very active in the policy area, and produces a large number of relevant statments and reports. To subscribe to the Royal Society E-Newsletter with updates on their latest policy activities you should email 'subscribe' to science.policy@royalsociety.org.
- Think tanks occasionally touch on scientific issues where they are deemed relevant. The Guardian has produced a list of some of the key think tanks. Newton's Apple (listed above) was established as a think tank that would deal specifically with science issues.
- The UK Resource Centre for Women in SET is an organisation which works with organisations, employers and policy makers to increase gender equality in science, engineering and technology (SET), and with individual women to help progress their SET careers.
Sunday, 6 June 2010
How to block Facebook applications
Short link for this post is http://is.gd/cEZIn
Click on any of the pictures to enlarge.
Edit 7 June 2010:
I might have just found a way of blocking all applications at once, by switching off 'platform applications' - if true, do this instead and ignore the text below :)
Account > Privacy settings > Scroll down to the bottom of the page > In 'Applications and websites' choose the link 'Edit your settings' > Click on 'Turn off' all platform applications.
This phrase appears in the section on 'Information accessible through your friends':
"Note: your name, Profile picture, gender, networks and user ID (along with any other information you've set to everyone) is available to friends' applications unless you turn off platform applications and websites."
-------------------------------------------------------------
This is how to block applications individually
Blocking a Facebook app is usually a two-step process - there doesn't appear to be a way to "block all apps except..." so it's a manual process for each one. Since Facebook apps can apparently access "your friends' info" (see blue highlight in the second screenshot below) then if I'm that friend I'd prefer that it didn't access my info. I assume the info is more than what is publicly available because if you're my friend you can see my entire profile.
If you want to find the apps that you're friends are currently using then, from your home / feed page, click on 'Applications' in the left hand side (see yellow highlight in first pic below), then the name of an application (highlighted in green below).
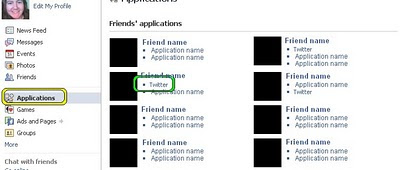
You'll be taken to a page that looks like this...
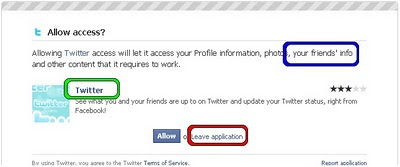
...here you need to click, again, on the name of the app (in green) and not on the part saying 'Leave application' (highlighted in red) - as far as I can see this is just a red herring to return you to your homepage and it doesn't block the app.
Once you've clicked you'll open up a new tab / window looking like the pic below. Click on the phrase 'Block application' (highlighted in pink) and a confirm window will appear, click to Block and then an acknowledgement will pop up to say that you've blocked the app.

You can now close the new page that opened, and go back to your profile in the original Facebook window.
Done.
If you want to block all applications from accessing any of your information I'm afraid you'll have to do this for each application, or put your friends on a limited profile view list.
If you are logged in to Facebook then you should be able to edit your Application settings by clicking on this link http://www.facebook.com/editapps.php?ref=mb or click on Account (top right) > Application settings. This shows you the apps that you are currently using or have authorised; you can delete or change their privacy settings here.
If you want to see all the applications you've currently blocked then follow this to get to the page: Account > Privacy settings > scroll to 'Block lists' and click on 'Edit your lists'.
Click on any of the pictures to enlarge.
Edit 7 June 2010:
I might have just found a way of blocking all applications at once, by switching off 'platform applications' - if true, do this instead and ignore the text below :)
Account > Privacy settings > Scroll down to the bottom of the page > In 'Applications and websites' choose the link 'Edit your settings' > Click on 'Turn off' all platform applications.
This phrase appears in the section on 'Information accessible through your friends':
"Note: your name, Profile picture, gender, networks and user ID (along with any other information you've set to everyone) is available to friends' applications unless you turn off platform applications and websites."
-------------------------------------------------------------
This is how to block applications individually
Blocking a Facebook app is usually a two-step process - there doesn't appear to be a way to "block all apps except..." so it's a manual process for each one. Since Facebook apps can apparently access "your friends' info" (see blue highlight in the second screenshot below) then if I'm that friend I'd prefer that it didn't access my info. I assume the info is more than what is publicly available because if you're my friend you can see my entire profile.
If you want to find the apps that you're friends are currently using then, from your home / feed page, click on 'Applications' in the left hand side (see yellow highlight in first pic below), then the name of an application (highlighted in green below).

You'll be taken to a page that looks like this...

...here you need to click, again, on the name of the app (in green) and not on the part saying 'Leave application' (highlighted in red) - as far as I can see this is just a red herring to return you to your homepage and it doesn't block the app.
Once you've clicked you'll open up a new tab / window looking like the pic below. Click on the phrase 'Block application' (highlighted in pink) and a confirm window will appear, click to Block and then an acknowledgement will pop up to say that you've blocked the app.

You can now close the new page that opened, and go back to your profile in the original Facebook window.
Done.
If you want to block all applications from accessing any of your information I'm afraid you'll have to do this for each application, or put your friends on a limited profile view list.
If you are logged in to Facebook then you should be able to edit your Application settings by clicking on this link http://www.facebook.com/editapps.php?ref=mb or click on Account (top right) > Application settings. This shows you the apps that you are currently using or have authorised; you can delete or change their privacy settings here.
If you want to see all the applications you've currently blocked then follow this to get to the page: Account > Privacy settings > scroll to 'Block lists' and click on 'Edit your lists'.
Saturday, 5 June 2010
How to find old tweets
Shortened link for this post is http://is.gd/cDtCN
What The Hashtag (taken over by What The Trend) is now providing some sort of coding information for people who know how to do something or other with JSON (evidently not me) and anyone who knows programming and apps and stuff can probably get create their own system. It's the same URL (http://wthashtag.com/) but it's now What the Trend API.
Edit: 8 July 2012
This post is out of date and kept here as an archive. See instead A list of tools for finding or capturing tweets (30 May 2011) - ironically it too is getting out of date ;)
The text below goes into some depth for a handful of tools but the 'list of tools' linked above covers a greater breadth but in less depth.
This post is out of date and kept here as an archive. See instead A list of tools for finding or capturing tweets (30 May 2011) - ironically it too is getting out of date ;)
The text below goes into some depth for a handful of tools but the 'list of tools' linked above covers a greater breadth but in less depth.
******************************************
UPDATE 7 July 2011: Google Realtime is no longer with us. Initially it seemed to be temporarily offline while under-bonnet tinkering happened and it was assumed it would be hooked up with Google+ however it now seems that Google is no longer accessing Twitter's stream as the deal ended on 2 July 2011. This isn't great.
******************************************
Edit: 19 May 2011Happy news, if you like curating hashtags - SearchHash will do what you want. It doesn't give you wee graphs with info on who's tweeted the most as What The Hashtag did but it lets you access (and export) your tweets. Here's @lesteph's blogpost introducing it.What The Hashtag (taken over by What The Trend) is now providing some sort of coding information for people who know how to do something or other with JSON (evidently not me) and anyone who knows programming and apps and stuff can probably get create their own system. It's the same URL (http://wthashtag.com/) but it's now What the Trend API.
Twapperkeeper does let you archive hashtags, but doesn't let you export them and it also lets you create only two (free) archives, which can be an archive of all your own tweets or someone else's. To maintain 5 archives it's $5 per month, 15 = $10 monthly and 25 archives are $15 monthly. If you're involved in higher education I think you can sort something out as part of JISC funding. @ASegar has written a detailed post explaining how to extract a hashtag transcript from a Twapperkeeper archive.
Edit: 14 April 2011
Google Updates mentioned below is now known as Google Realtime. What the Hashtag is no longer functioning (wail!) and Twapperkeeper permits only two free archives to be created per user. Twitter has changed its Terms of Service making it much harder to archive tweets, let alone find them.
Edit: 6 June 2010
A couple of other thoughts - Favotter (http://en.favotter.net) records all favourited tweets (the ones you star, or other people star) so you can search for your, or someone else's, username there. Note that the service appears to have gone dead as of 8 May 2010 and is no longer collecting tweets. An alternative is Favstar (http://favstar.fm/) which is still going strong, but isn't a free service so limited functionality but pretty good all the same.
Another service that I've yet to investigate fully is the search engine Twoogel (http://twoogel.com/) it uses Google functionality (eg inurl: or site: ) but I've tried it and it's not picking up much individual stuff at the moment (36 tweets of mine, out of about 9,000) but it picked up over 100 tweets from the Science Communication Conference when I searched for it by hashtag #scc2010).
Of course if I'd done better research I'd have saved myself writing this as Loic Le Meur has already written what is probably the definitive post, and it's likelier to attract more comments and new suggestions so recommend visiting it:
http://loiclemeur.com/english/2010/04/how-to-find-old-tweets.html
-------------------------------
In a short while this post will be redundant as Google is unveiling a searchable archive of ALL tweets (scroll down the page to see more and how to use the pilot version) but there are other ways of finding your previous tweets. Not any more it isn't, see bit in red above.
Tools to back up your tweets
I've not included any information on tools that will save your tweets for you (you can use Twapperkeeper for this http://twapperkeeper.com/index.php though it goes only as far as 2009, and there are other tools).
Twitter search
Twitter's own search engine is well known for being a bit useless in finding old tweets - 'Old tweets are temporarily unavailable' being a typical response when looking for something. Edit: Twitter's search has got better (2011) but still goes back only a few days. Services like Chirpstory or Storify can go a bit further back in time than Twitter.
I use FriendFeed to search my previous tweets - they are all there, eg http://twitter.com/JoBrodie/statuses/2236469325 - from June 19 2009, but you can't hack that Twitter URL (ie tweak the numeric part from 2, 236,469,325 to 2,236,469,324 etc) to find older tweets.
This is a real shame - you used to be able to do something similar before they brought in the 'More' button that appears at the bottom of the page. It used to read 'older' and it allowed you to go backwards through pages of tweets, but each page had its own URL (doesn't now) and so you could easily amend the URL to go from page 200 to page 1 very quickly. The new 'More' system just refreshes the page with another 20 previous tweets, but the URL doesn't change, meaning it's much harder to interact with it.
Rolling back the pages of your tweets
You can tweak the 'More' button URL a tiny bit, but it doesn't go all the way back to your Tweet Zero.
First catch your URL
Go to your own Twitter profile, mine's http://twitter.com/JoBrodie and then scroll to the bottom of your page. Hover over 'More' and note the URL that appears in the status bar at the bottom of the window (if you don't have status bar on, make sure it's ticked in the View or View > Toolbar menu).
Unfortunately it doesn't seem to be possible to 'right click, save location' as usual, which would let you copy the URL quickly, so at this point I press the print screen (PrtSc) button and paste the screenshot into Paint (Start > Run > mspaint). This means I don't have to keep hovering over the More button to see the text, the text is now 'trapped' in the resulting screenshot. It also means I have to manually type the URL by hand.
The URL given in my 'More' button reads (shown highlighted by a purple oval below):
http://twitter.com/jobrodie?max_id=15477934370&page=2&twttr=true - typing this into a new browser window will take you to page 2 of my tweets (the content of this page will change because page one of my tweets will always contain whatever are the most recent tweets I posted).
I think you can safely delete the &twttr=true bit, all you really need to change is &page=2 - I managed to go as far back as &page=160 - I've not been able to get it to bring up any older pages (I've tried this on another twitter account too) so http://twitter.com/jobrodie?max_id=15477934370&page=160 is as far back as I can go in time using this method.
However, we've already seen that Twitter still has all the older tweets, but that they're largely inaccessible at the moment... on to FriendFeed.
Importing your tweets into FriendFeed and using their search
I've always used FriendFeed if I ever want to find any of my old tweets (I've found my first tweet http://twitter.com/JoBrodie/statuses/841825864) by using their much more powerful search engine. This does rely on having a FriendFeed account (I recommend this) and also on remembering keywords you've used in your tweets, so that you can use them as search words.
You can search other people's tweets too either by subscribing to their FriendFeed account, if they have one. If they don't have an account, but their Twitter feed isn't locked, then you can still use FriendFeed - you need to create an 'imaginary friend' account for them and import their twitter feed to that. I've previously written a how to blog on this:
Cunning use of FriendFeed - find old tweets, yours or others
http://brodiesnotes.blogspot.com/2009/12/cunning-use-of-friendfeed-find-old.html
Google will soon be archiving all tweets
Sometimes though you might want to find out what has been said on a topic without knowing exactly the words that may have been used. It looks like Google might be on the case with this, as it rolled out (in April, I'm just catching up) a searchable archive of Twitter. At the moment it only goes as far as February 2010 but according to Google's blog their intention is for it to go back to Day One of Twitter, in 2006.
Below are a series of screenshot showing how to access and use it - the fourth screen shows active links for year (2010) and month (February) and I assume these will eventually be populated with links that will let you scroll back to 2006. I think this could be very useful.
1. As an example to show how the pilot system works I've typed a word that was popular on Twitter recently into Google...

2. The search results, after pressing enter, are shown below... click on 'More', highlighted in the picture below with a purple oval.

3. Clicking on More brings up several options to filter your results, choose Updates...

4. This will now search within Twitter updates... currently the system is set to today's date (June 2010) but you can click on these as links to bring up an option to choose a different period in time.

5. Clicking on 2010 brings up the entire year for 2010 - however at the moment this is only Feb to June because that's all that Google's making available at the moment during the pilot. Clicking on a month, in the pic below I've highlighted February...

6. ...expands the window to include all mentions of your keyword that were tweeted in February.

I recommend having a bit of a play around with it.
Keywords - I've put them here because Blogger refuses to update this post with all the ampersands in the keywords. I can't see what ampersands it's talking about to be honest but I've given up fighting with Blogger's ridiculous formatting demands. One day someone will work out how to make a blogging platform manage text (and no, it's not WordPress either I'm afraid, if anything it's worse).
"how to", "twitter tips", archived tweets, finding old tweets, how to find old tweets, tweet history, twitter archive
Edit: 14 April 2011
Edit: 6 June 2010
Another service that I've yet to investigate fully is the search engine Twoogel (http://twoogel.com/) it uses Google functionality (eg inurl: or site: ) but I've tried it and it's not picking up much individual stuff at the moment (36 tweets of mine, out of about 9,000) but it picked up over 100 tweets from the Science Communication Conference when I searched for it by hashtag #scc2010).
Of course if I'd done better research I'd have saved myself writing this as Loic Le Meur has already written what is probably the definitive post, and it's likelier to attract more comments and new suggestions so recommend visiting it:
http://loiclemeur.com/english/2010/04/how-to-find-old-tweets.html
-------------------------------
Tools to back up your tweets
I've not included any information on tools that will save your tweets for you (you can use Twapperkeeper for this http://twapperkeeper.com/index.php though it goes only as far as 2009, and there are other tools).
Twitter search
Twitter's own search engine is well known for being a bit useless in finding old tweets - 'Old tweets are temporarily unavailable' being a typical response when looking for something. Edit: Twitter's search has got better (2011) but still goes back only a few days. Services like Chirpstory or Storify can go a bit further back in time than Twitter.
I use FriendFeed to search my previous tweets - they are all there, eg http://twitter.com/JoBrodie/statuses/2236469325 - from June 19 2009, but you can't hack that Twitter URL (ie tweak the numeric part from 2, 236,469,325 to 2,236,469,324 etc) to find older tweets.
This is a real shame - you used to be able to do something similar before they brought in the 'More' button that appears at the bottom of the page. It used to read 'older' and it allowed you to go backwards through pages of tweets, but each page had its own URL (doesn't now) and so you could easily amend the URL to go from page 200 to page 1 very quickly. The new 'More' system just refreshes the page with another 20 previous tweets, but the URL doesn't change, meaning it's much harder to interact with it.
You can tweak the 'More' button URL a tiny bit, but it doesn't go all the way back to your Tweet Zero.
Go to your own Twitter profile, mine's http://twitter.com/JoBrodie and then scroll to the bottom of your page. Hover over 'More' and note the URL that appears in the status bar at the bottom of the window (if you don't have status bar on, make sure it's ticked in the View or View > Toolbar menu).

However, we've already seen that Twitter still has all the older tweets, but that they're largely inaccessible at the moment... on to FriendFeed.
Importing your tweets into FriendFeed and using their search
I've always used FriendFeed if I ever want to find any of my old tweets (I've found my first tweet http://twitter.com/JoBrodie/statuses/841825864) by using their much more powerful search engine. This does rely on having a FriendFeed account (I recommend this) and also on remembering keywords you've used in your tweets, so that you can use them as search words.
You can search other people's tweets too either by subscribing to their FriendFeed account, if they have one. If they don't have an account, but their Twitter feed isn't locked, then you can still use FriendFeed - you need to create an 'imaginary friend' account for them and import their twitter feed to that. I've previously written a how to blog on this:
Cunning use of FriendFeed - find old tweets, yours or others
http://brodiesnotes.blogspot.com/2009/12/cunning-use-of-friendfeed-find-old.html
Sometimes though you might want to find out what has been said on a topic without knowing exactly the words that may have been used. It looks like Google might be on the case with this, as it rolled out (in April, I'm just catching up) a searchable archive of Twitter. At the moment it only goes as far as February 2010 but according to Google's blog their intention is for it to go back to Day One of Twitter, in 2006.

2. The search results, after pressing enter, are shown below... click on 'More', highlighted in the picture below with a purple oval.





Keywords - I've put them here because Blogger refuses to update this post with all the ampersands in the keywords. I can't see what ampersands it's talking about to be honest but I've given up fighting with Blogger's ridiculous formatting demands. One day someone will work out how to make a blogging platform manage text (and no, it's not WordPress either I'm afraid, if anything it's worse).
"how to", "twitter tips", archived tweets, finding old tweets, how to find old tweets, tweet history, twitter archive
Subscribe to:
Posts (Atom)



